智能体开发新范式:Blades 架构下的高效 Agent & Workflow 实践
什么是 Agent(智能体)?
Section titled “什么是 Agent(智能体)?”业界对 Agent 并没有一个统一、严格的定义。不同厂商、开源社区甚至论文体系中,对 Agent 的描述都略有差异。但整体来看,Agent 通常指 能够长期自主运行、具备一定决策能力、并能根据任务需要调用多种外部工具的智能系统。
它可以表现为一个“懂目标、会判断、能执行”的程序,也可以是传统意义上基于规则的固定流程机器人。
在 Blades 中,我们把这些不同形态统称为 智能体系统(Agentic Systems)。尽管它们都属于 Agent 范畴,但在实际架构设计时,需要特别区分两个核心概念:工作流(Workflow) 与 智能体(Agent)。
工作流(Workflow)
Section titled “工作流(Workflow)”工作流更偏向传统软件的思想:它依赖 预先定义好的执行步骤 来组织 LLM 与工具的调用关系,一切的逻辑顺序都由开发者提前规划、写死在流程图或代码中。
特点:
- 执行路径是固定的、可预期的
- 每一步的输入、输出、条件分支都由开发人员提前设定
- 更适用于业务流程标准化、稳定、可拆分的任务
- 易于控制边界、测试与审计
一句话:它是模型按照流程走,而不是流程根据模型变。
智能体(Agent)
Section titled “智能体(Agent)”Agent 的核心价值在于“自主性”和“适应性”。它不是按照流程图运行,而是让 LLM 作为“大脑”,根据任务目标与当前状态,动态决定下一步做什么。
Agent 的典型能力包括:
- 由 LLM 自主决定 执行步骤,而不是依赖预设流程
- 能够自主选择、组合或多轮调用外部工具
- 在执行过程中具有对任务全局状态的“记忆”和“理解”
- 根据实时反馈动态改变策略,而不是固定走分支
- 某些情况下可以持续运行,类似“服务型 Agent”
因此相比 Workflow,Agent 更接近一个主动的执行者,而不是被动的流程节点。
一句话:工作流是“流程在控制模型”,而 Agent 是“模型在控制流程”。
使用 Blades 构建:智能体(Agent)
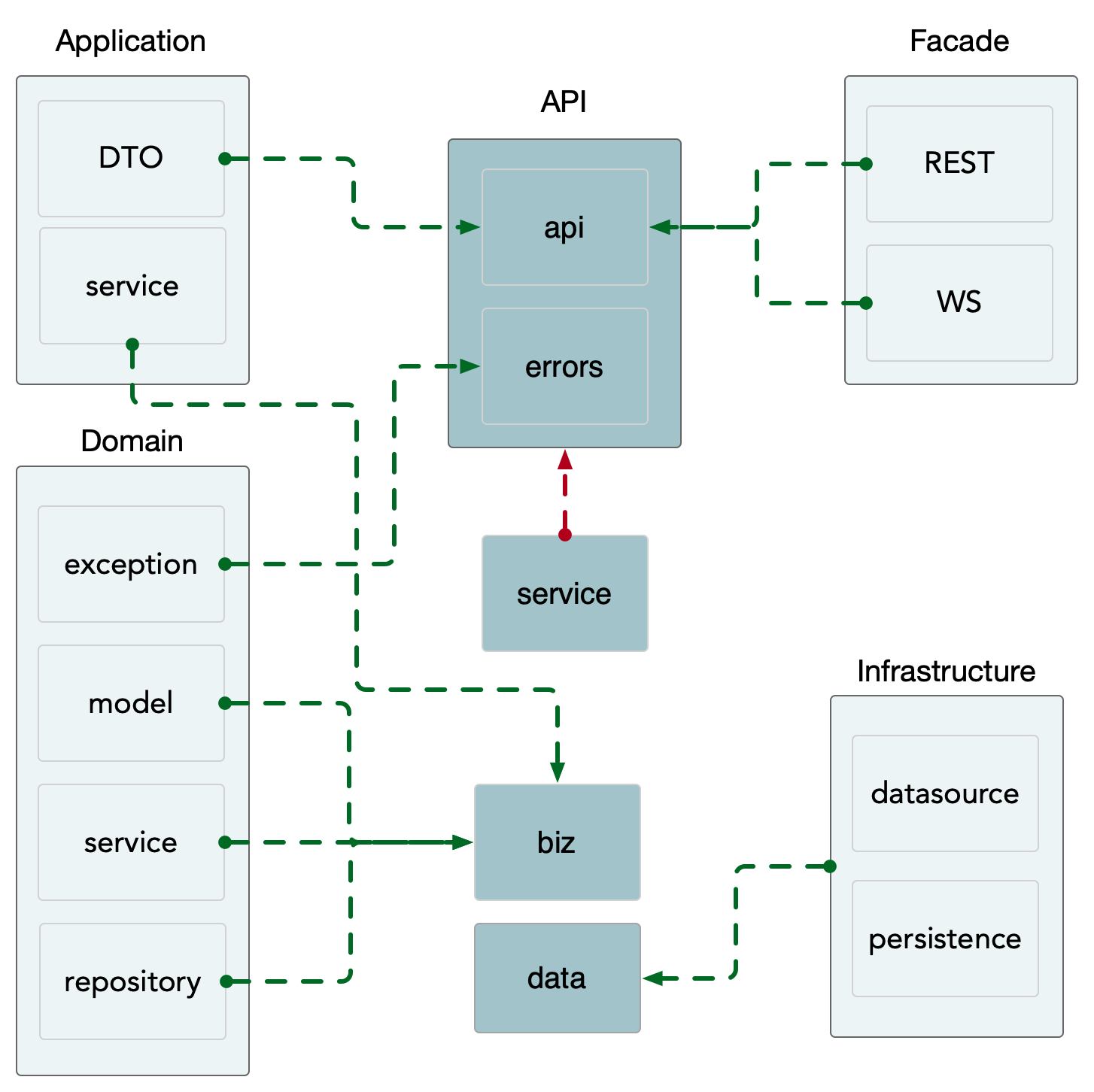
Section titled “使用 Blades 构建:智能体(Agent)”Blades 基于 Go 语言的简洁语法和高并发特性,提供了灵活、可扩展的 Agent 架构。其设计理念是通过统一的接口和可插拔式组件,让开发者能够在保持高性能的同时,轻松扩展 Agent 的能力。 整体架构如下:
在 Blades 中,可以通过 blades.NewAgent 创建一个智能体(Agent)。Agent 是整个框架的核心组件,主要负责:
- 调用 LLM 模型
- 管理工具(Tools)
- 执行提示词(Prompts)
- 控制整个任务的运行流程
同时,Blades 提供了简单优雅的方式来自定义工具,可以使用 tools.NewTool 或者 tools.NewFunc 进行构建工具,让 Agent 能够访问外部 API、业务逻辑或计算能力。
下面是一个自定义天气查询工具的示例:
// 定义天气处理逻辑func weatherHandle(ctx context.Context, req WeatherReq) (WeatherRes, error) { return WeatherRes{Forecast: "Sunny, 25°C"}, nil}// 创建一个天气工具func createWeatherTool() (tools.Tool, error) { return tools.NewFunc( "get_weather", "Get the current weather for a given city", weatherHandle, )}再构建一个可调用天气工具的智能助手(Weather Agent):
// 配置所调用的模型和地址model := openai.NewModel("deepseek-chat", openai.Config{ BaseURL: "https://api.deepseek.com", APIKey: os.Getenv("YOUR_API_KEY"),})// 创建一个天气智能助手agent, err := blades.NewAgent( "Weather Agent", blades.WithModel(model), blades.WithInstruction("You are a helpful assistant that provides weather information."), blades.WithTools(createWeatherTool()),)if err != nil { log.Fatal(err)}// 实现查询上海的天气信息input := blades.UserMessage("What is the weather in Shanghai City?")runner := blades.NewRunner(agent)output, err := runner.Run(context.Background(), input)if err != nil { log.Fatal(err)}log.Println(output.Text())使用 Blades 的框架设计,你只需少量代码就能快速构建一个既能调用工具又能自主决策的智能体。
接下来,我们将基于 Blades 框架介绍几种典型的工作流模式,每种设计模式适用于不同的业务场景,从最简单的线性流程,到高度自治的智能体,可以根据实际业务需求选择合适的设计方式。
模式 1:Chain Workflow(串联工作流)
Section titled “模式 1:Chain Workflow(串联工作流)”该模式体现了“将复杂任务拆分为简单步骤”的原则。 适用场景:
- 任务本身具有明确的、顺序分明的步骤。
- 想以牺牲少许延迟换取更高准确度。
- 每个步骤都依赖前一个步骤的输出。
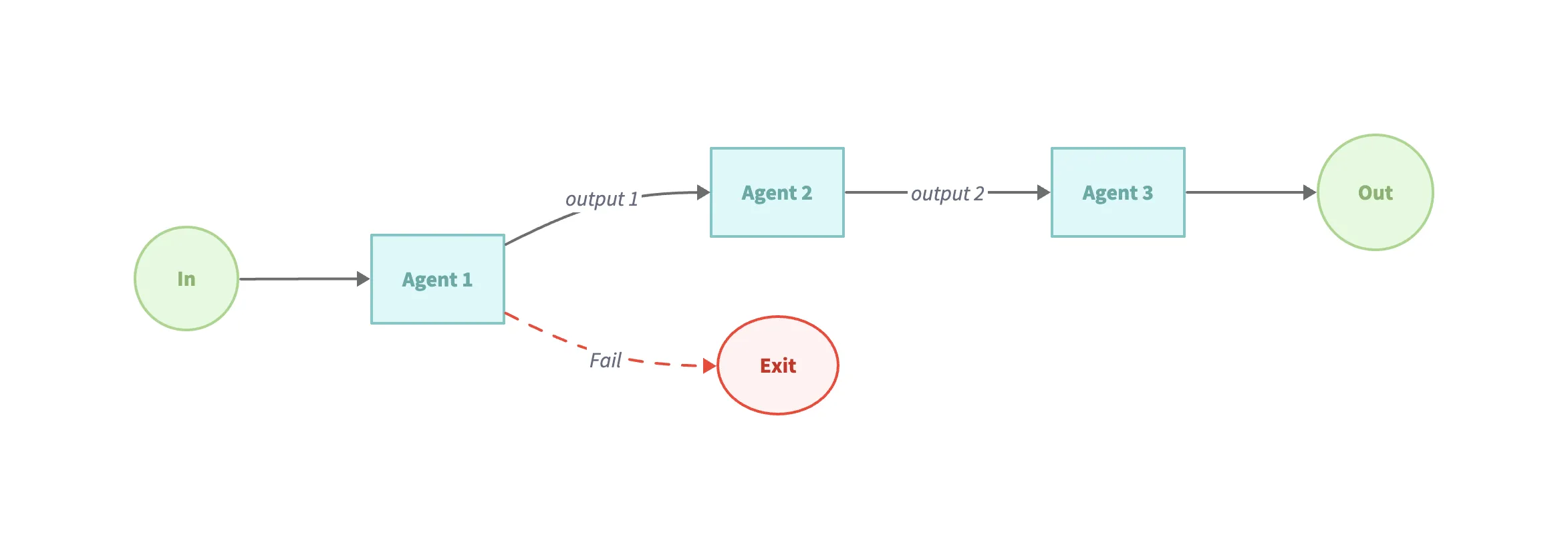
示例代码(examples/workflow-sequential):
// 串行工作流,进行按编排顺序执行智能体sequentialAgent := flow.NewSequentialAgent(flow.SequentialConfig{ Name: "WritingReviewFlow", SubAgents: []blades.Agent{ writerAgent, reviewerAgent, },})模式 2:Parallelization Workflow(并行工作流)
Section titled “模式 2:Parallelization Workflow(并行工作流)”该模式用于让 LLM 同时处理多个子任务,然后将结果汇总。
适用场景:
- 需要处理大量“相似但独立”的项。
- 任务需要多个不同视角。
- 时间敏感、任务可并行化。
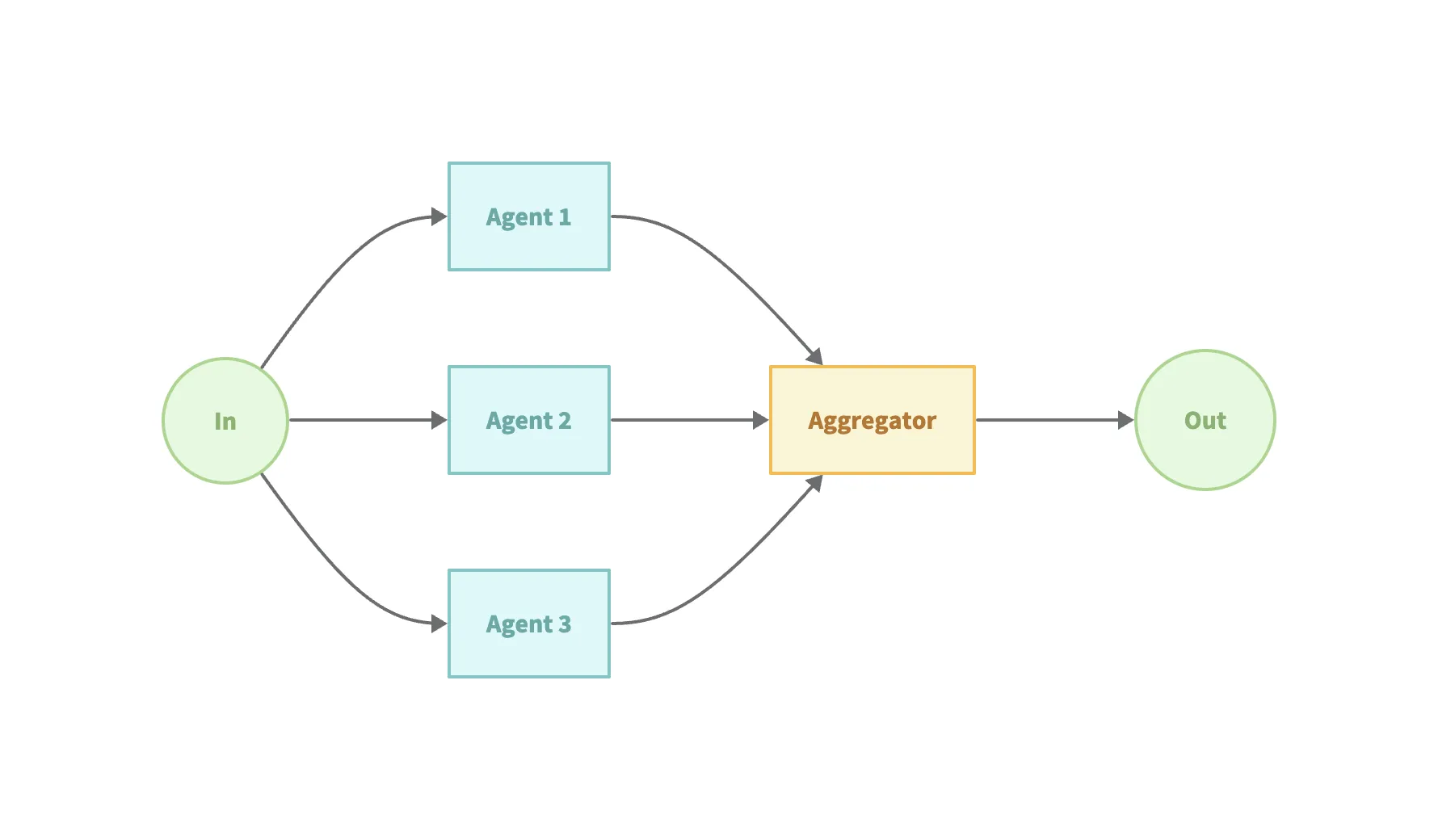
示例代码(examples/workflow-parallel):
// 并行工作流,通过把生成的结果存到 session state 中,后续流程进行引用parallelAgent := flow.NewParallelAgent(flow.ParallelConfig{ Name: "EditorParallelAgent", Description: "Edits the drafted paragraph in parallel for grammar and style.", SubAgents: []blades.Agent{ editorAgent1, editorAgent2, },})// 定义串行工作流,实现同时与并行定义sequentialAgent := flow.NewSequentialAgent(flow.SequentialConfig{ Name: "WritingSequenceAgent", Description: "Drafts, edits, and reviews a paragraph about climate change.", SubAgents: []blades.Agent{ writerAgent, parallelAgent, reviewerAgent, },})这种模式能显著提升吞吐量,但也要注意并行带来的资源消耗与复杂性。
模式 3:Routing Workflow(路由工作流)
Section titled “模式 3:Routing Workflow(路由工作流)”这个模式通过 LLM 智能判断输入类型,再将其分派给不同处理流程。 适用场景:
- 输入类别多、结构差异大。
- 各类输入需不同专用处理流程。
- 分类准确率较高。
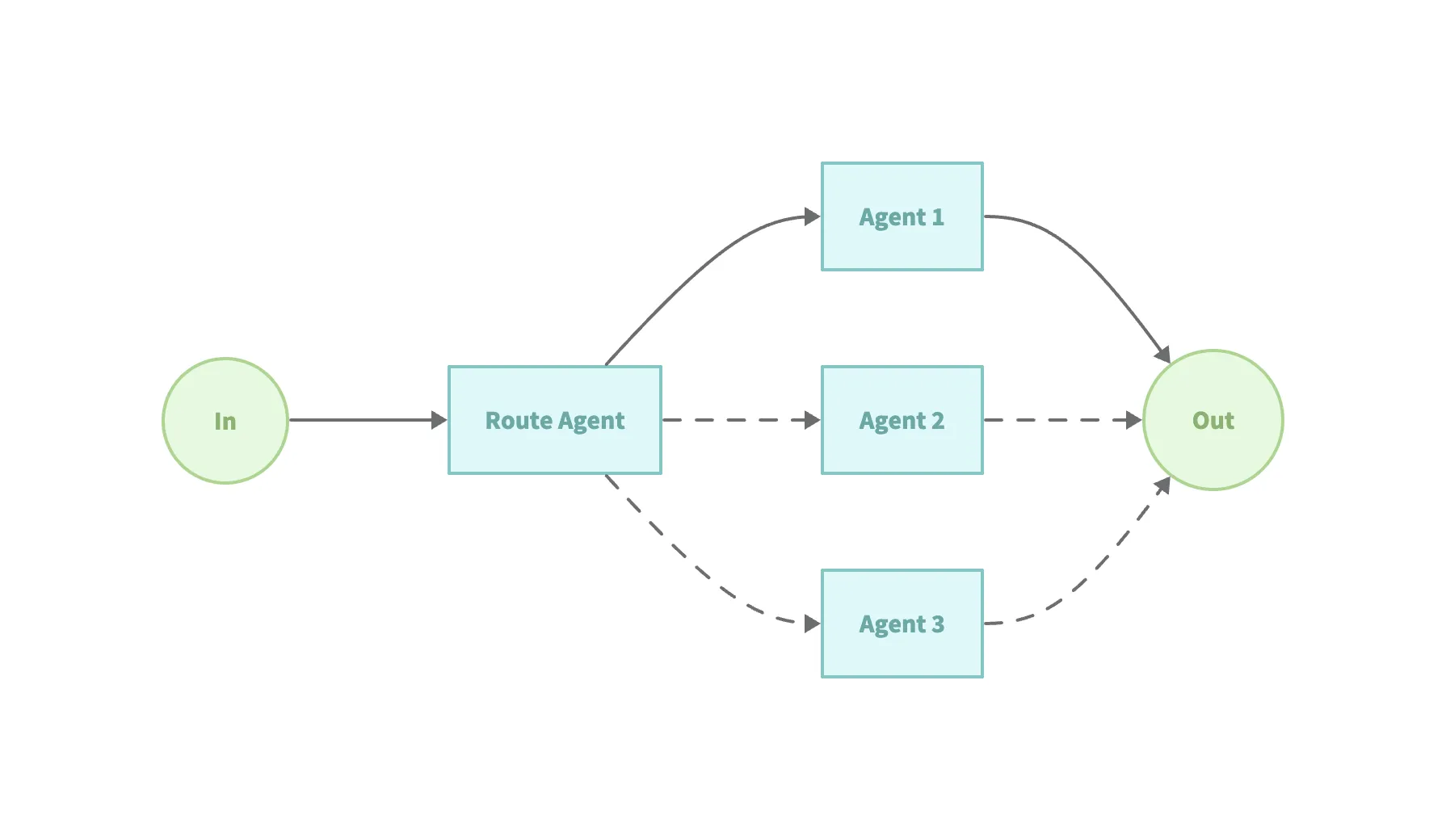
示例代码(examples/workflow-routing):
// 通过 Agent 中的 description 进行自动选择合适的专家智能体agent, err := flow.NewRoutingAgent(flow.RoutingConfig{ Name: "TriageAgent", Description: "You determine which agent to use based on the user's homework question", Model: model, SubAgents: []blades.Agent{ mathTutorAgent, historyTutorAgent, },})模式 4:Orchestrator-Workers(编排-工作者模式)
Section titled “模式 4:Orchestrator-Workers(编排-工作者模式)”这个模式结合了 “Agent” 倾向:一个中央 LLM 作任务分解(orchestrator),再由不同 “Worker” 执行子任务。
适用场景:
- 无法事先完全预测子任务。
- 任务需要多种视角或处理方法。
- 需要系统的适应性与复杂决策流程。
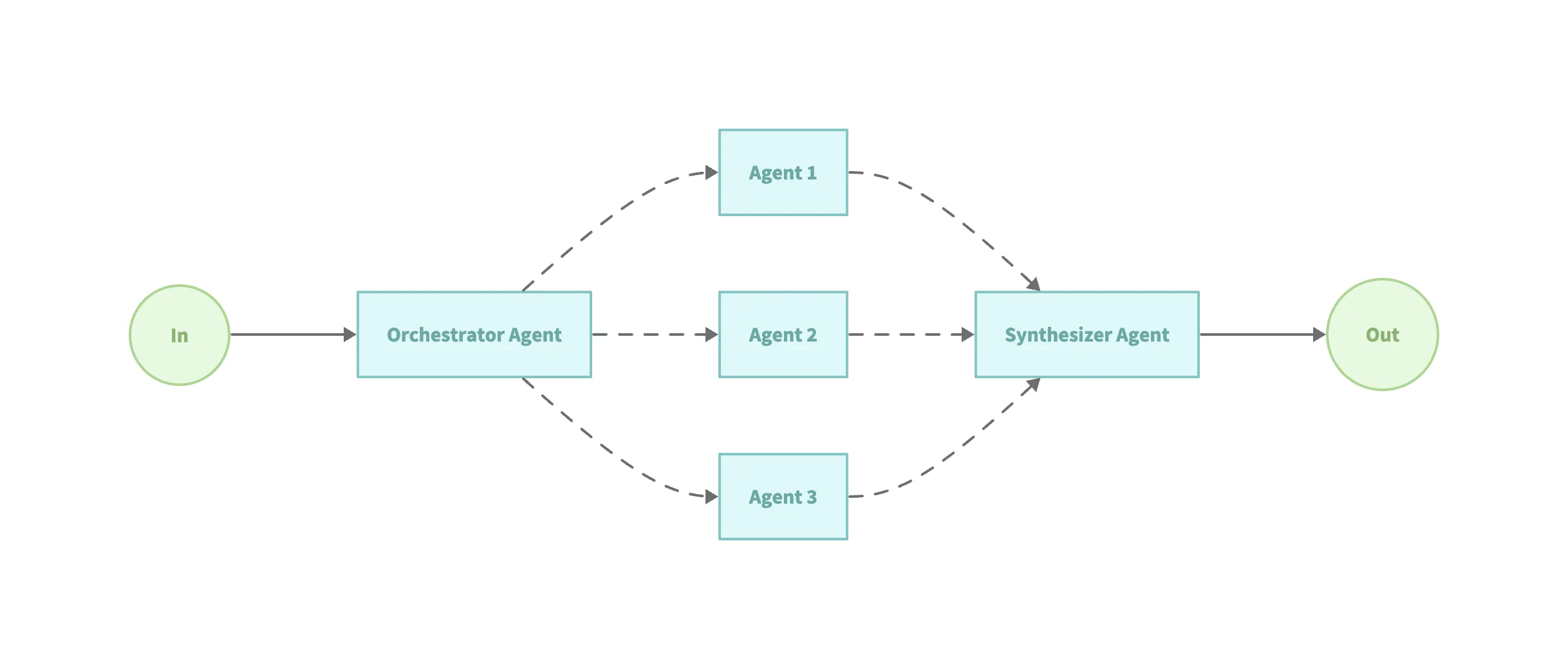
示例代码(examples/workflow-orchestrator):
// 通过工具定义翻译器(Agent as a Tool)translatorWorkers := createTranslatorWorkers(model)// 协调器进行选择需要的工具进行执行orchestratorAgent, err := blades.NewAgent( "orchestrator_agent", blades.WithInstruction(`You are a translation agent. You use the tools given to you to translate. If asked for multiple translations, you call the relevant tools in order. You never translate on your own, you always use the provided tools.`), blades.WithModel(model), blades.WithTools(translatorWorkers...),)// 进行合成生成的多个结果synthesizerAgent, err := blades.NewAgent( "synthesizer_agent", blades.WithInstruction("You inspect translations, correct them if needed, and produce a final concatenated response."), blades.WithModel(model),)模式 5:Evaluator-Optimizer(评估-优化模式)
Section titled “模式 5:Evaluator-Optimizer(评估-优化模式)”该模式中,一个模型生成输出,另一个模型评估该输出并提供反馈,如同人类“先写后改”流程。 适用场景:
- 有明确可量化的评估标准。
- 通过多轮“生成→评估→改进”能显著提升质量。
- 任务适合反复迭代。
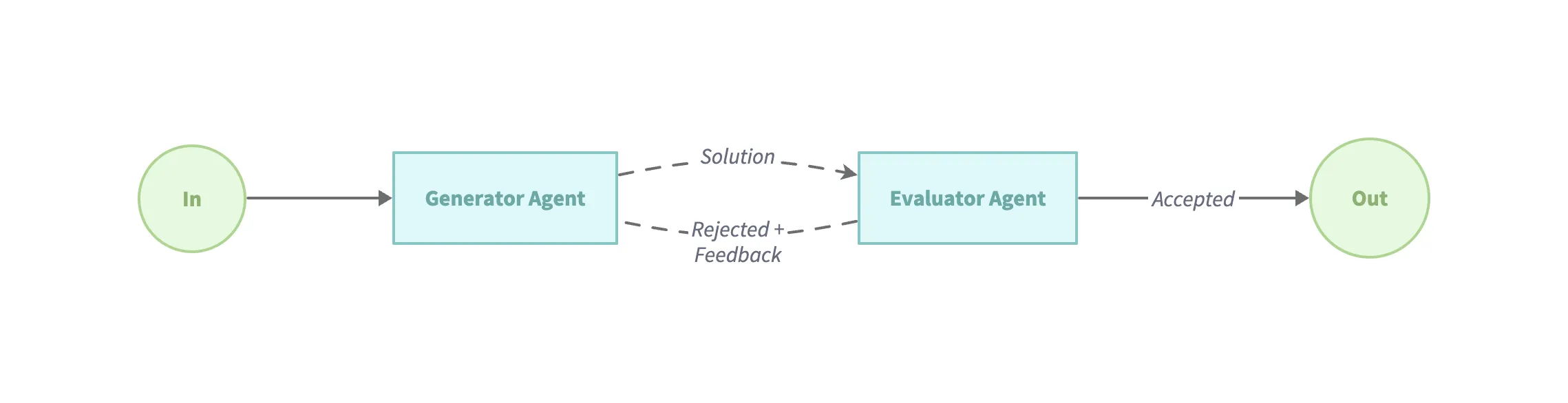
示例代码(examples/workflow-loop):
// 通过生成内容,再进行评估效果,反复实现多次迭代loopAgent := flow.NewLoopAgent(flow.LoopConfig{ Name: "WritingReviewFlow", Description: "An agent that loops between writing and reviewing until the draft is good.", MaxIterations: 3, Condition: func(ctx context.Context, output *blades.Message) (bool, error) { // 评估内容效果判断是否结束迭代 return !strings.Contains(output.Text(), "The draft is good"), nil }, SubAgents: []blades.Agent{ writerAgent, reviewerAgent, },})最佳实践与建议
Section titled “最佳实践与建议”在业务实践中,不管是单一智能体还是多智能体架构,工程设计往往比模型能力更决定最终效果。
以下实践建议总结了实际项目中最关键的原则,可作为设计与实现智能体时作为参考。
从简单做起
- 先构建基础工作流,再考虑更复杂的智能体。
- 用最简单能满足需求的模式。
设计可靠性
- 明确错误处理机制。
- 尽量使用类型安全响应。
- 每一步加上验证。
权衡取舍
- 在延迟与准确率之间做平衡。
- 是否并行要评估场景。